Um pouco de conceitos: overfitting & resampling
Apesar de serem termos recorrentes em machine learning, resampling e overfitting são frequentemente discutidos apenas na prática, muitas vezes sem a sua compreensão. Neste post1, tentarei introduzir os conceitos de forma genérica.
O PROCESSO DE AJUSTE E O SOBREAJUSTE
Considere uma função de ajuste \(f\), um conjunto de pontos \(D = {d_1, ..., d_n}\) com \(d_i = (x_i y_i)´\), variáveis de decisão ou parâmetros \(x_i \in \R^m\) e imagem \(y_i = f(x_i) \in \R\). Diferentemente da abordagem clássica, em que, no caso do modelo clássico de regressão linear, há um modelo teórico de coeficientes estimados por mínimos quadrados ordinários (MQO) que é garantido pelo teorema de Gauss-Markov ser o melhor estimador linear não viesado (BLUE), em machine learning o objetivo é encontrar, de forma iterativa, um meta-modelo que melhor aproxima a função \(f\) usando a informação contida em \(D\), ou seja, queremos ajustar uma função de regressão \(\hat{f}_D\) aos nossos dados \(D\) de forma que \(\hat{y} = \hat{f}_D(x, \varepsilon)\) tenha o menor erro de aproximação \(\varepsilon\).
Para verificar o quão bem o modelo \(\hat{f}_D\) se aproxima da função real \(f\), é necessário uma função de perda \(L(y, \hat{f}(x))\) que, no caso de regressão, será a perda quadrática \((y - \hat{f}(y))^2\) ou a perda absoluta \(|y - \hat{f}(y)|\). Esses valores são agregados pela média para formar as funções de custo erro médio quadrático (MSE) e erro médio absoluto (MAE).
Dada a função de perda, pode-se definir o risco associado ao modelo de função de ajuste \[R(f, p) = \int_{\R}{}\int_{\R^m}{} L(y, f(x))p(x, y)dxdy\] em que \(p(x, y)\) é a função densidade de probabilidade conjunta. Como não temos a função real mas procuramos uma função estimada que se aproxime dela, temos \[GE(\hat{f}_D, p) = \int_{\R}{}\int_{\R^m}{} L(y, \hat{f}_D(x))p(x, y)dxdy \tag{1}\] que é o erro de generalização ou risco condicional associado ao preditor.
Então, podemos estimar o erro de generalização do modelo. Como não conhecemos a distribuição \(P\), a substituímos pela amostra de teste \(D^*\) e ficamos com \[\widehat{GE}(\hat{f}_D, D^*) = \sum_{(xy)´ \in D^*} \frac{L(y, \hat{f}_D(x))}{|D^*|}\] Se substituirmos a amostra teste pela amostra treino \(D\) usada para ajustar o modelo, teremos o chamado erro de resubstituição \[\widehat{GE}_\text{resub} = \widehat{GE}(\hat{f}_D, D)\] Naturalmente, nesse caso estaríamos usando os dados de treino tanto para treinar o preditor quanto para estimar o erro de generalização, o que nos levaria a uma estimativa enviesada do erro de generalização. Caso usássemos essa estimativa para seleção de modelos, esse viés favoreceria modelos mais adaptados à amostra.
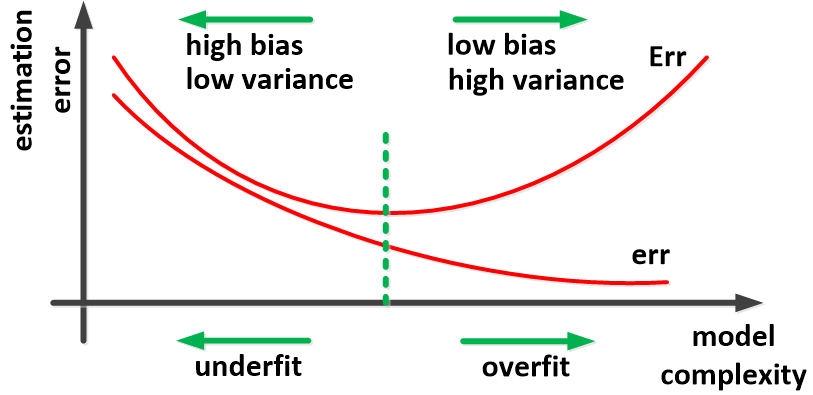
O problema é que nesses modelos, dadas suficientes iterações, o erro de resubstituição tende a zero. Isso acontece porque conforme o preditor se adapta cada vez mais aos dados de treinamento ele irá memorizar a relação entre o conjunto de pontos \(D\) e a imagem \(f(x_i)\), ou seja, irá se ajustar perfeitamente ao formato da função a ser modelada. E não necessariamente um modelo perfeitamente ajustado se traduz na capacidade de predição de dados futuros (fora da amostra).
De forma geral, espera-se que o preditor reduza seu viés durante o treino apenas o suficiente para que seja capaz de generalizar sua predição para fora da amostra em um nível ótimo de acurácia. A partir desse ponto, a redução no viés é penalizada com o aumento da variância, ou seja, com a redução de sua capacidade de prever dados futuros. A esse processo se dá o nome de overfitting ou sobreajuste. Isso quer dizer que não podemos considerar a performance do preditor em \(D\) se desejamos estimar honestamente a performance real do modelo.
REAMOSTRAGEM
Uma forma de se corrigir esse problema é dividindo a amostra em um conjunto para treino \(D_\text{treino}\) e outro conjunto para teste \(D_\text{teste}\) de forma que \(D_\text{treino} \cup D_\text{teste} = D\) e \(D_\text{treino} \cap D_\text{teste} = \empty\). Assim, pode-se treinar o modelo em \(D_\text{treino}\) para se obter \(\hat{f}_{D_{\text{treino}}}\) e calcular seu erro de generalização usando os dados de \(D_\text{teste}\). Essa abordagem é chamada de hold-out e ela é de simples implementação e utilização, uma vez que as observações do conjunto teste são completamente independentes das observações com as quais o modelo foi treinado. A estimativa do erro de generalização então se torna \[\widehat{GE}_\text{hold-out} = \widehat{GE}(\hat{f}_{D_{\text{treino}}}, D_{\text{teste}})\] Dois problemas permanecem:
É necessária uma amostra grande, uma vez que deve-se ter dados suficientes tanto na amostra treino para ajustar um modelo adequado, quanto na amostra teste para realizar uma avaliação de performance estatisticamente válida.
Esse método não é suficiente para detectar variância e instabilidades na amostra treino. Modelos mais complexos, especialmente não lineares, podem produzir resultados muito diferentes com mudanças pequenas nos dados de treino.
É exatamente para lidar com essas situações que foram desenvolvidas as técnicas de reamostragem. Todas essas tecnicas geram repetidamente \(i\) subconjuntos de treino \(D_{\text{treino}}^{(i)}\) e teste \(D_{\text{teste}}^{(i)}\) com o dataset disponível, ajustam um modelo com cada conjunto de treino e atestam sua qualidade no conjunto de teste correspondente. A estimativa do erro de generalização então se torna \[\widehat{GE}_\text{samp} = \frac{1}{k}\sum_{i=1}^{k}\widehat{GE}(\hat{f}_{D_{\text{treino}}^{(i)}}, D_{\text{teste}}^{(i)}) \tag{2}\] O erro de generalização dado na equação (1) depende tanto do tamanho da amostra usada para treinar quanto para testar o modelo ajustado. Portanto, devemos garantir que o tamanho da amostra usado para verificar o erro de generalização de um modelo estimado a partir de \(n\) data points seja próximo de n. Se, por exemplo, o conjunto de treino for muito menor que a amostra total o erro será superestimado, uma vez que muito menos informação foi usada para calcular o estimador.
Da mesma forma, a qualidade do estimador do erro de generalização obtido em (2) a partir de uma estratégia de reamostragem também depende muito do tamanho dos conjuntos \(D^{(i)}\) em relação à amostra original, da quantidade \(k\) de subconjuntos utilizados e da estrutura de dependência entre os subconjuntos \(D^{(i)}\) — novamente, modelos mais complexos são mais sensíveis a alterações no dataset e a variância entre os subconjuntos tende a ser maior. O erro do estimador é geralmente medido pelo erro médio quadrático (MSE): \[\text{MSE}(\widehat{GE}_\text{samp}) = \mathbb{E}[(\widehat{GE}_\text{samp} - GE(\hat{f}_D, P))^2]\] Esse estimador também pode ser representado como a soma do quadrado do viés e a variância: \[\text{MSE}(\widehat{GE}_\text{samp}) = \text{Bias}(\widehat{GE}_\text{samp})^2 + \text{Variância}(\widehat{GE}_\text{samp})\] Sendo que o viés expressa a diferença média entre um estimador e o valor real, enquanto a variância mede a dispersão média do estimador. Essas quantidades são definidas da seguinte forma: \[\text{Bias}(\widehat{GE}_\text{samp}) = \mathbb{E}[\widehat{GE}_\text{samp}] - \mathbb{E}[GE(\hat{f}_D, p)]\] e \[\text{Variância}(\widehat{GE}_\text{samp}) = \mathbb{E}[(\widehat{GE}_\text{samp} - \mathbb{E}[\widehat{GE}_\text{samp}])^2]\]
POR FIM
Com essa introdução, espero que os conceitos tenham ficado mais claros e que tenha ajudado um pouco na compreensão da meta modelagem. Tenho certeza que eu não verei os resultados da mesma forma na próxima que vez que aplicar técnicas de reamostragem para seleção e tuning de meus modelos!
CITAÇÃO
Para citar esse post, use:
Alberson Miranda. Apr 17, 2021. "Um pouco de conceitos: overfitting & resampling". https://datamares.netlify.app/post/overfitting-resampling/.
Ou a entrada em BibTex:
@misc{datamares,
title = {Um pouco de conceitos: overfitting & resampling},
author = {Alberson Miranda},
year = {2021},
url = {https://datamares.netlify.app/post/overfitting-resampling/}
}
REFERÊNCIAS
Totalmente apoiado em (Bischl B. 2012).↩︎